I built Chonkie because I was tired of rewriting chunking code for RAG applications. Existing libraries were either too bloated (80MB+) or too basic, with no middle ground.
Core features:
- 21MB default install vs 80-171MB alternatives
- 33x faster token chunking than popular alternatives
- Supports multiple chunking strategies: token, word, sentence, and semantic
- Works with all major tokenizers (transformers, tokenizers, tiktoken)
- Zero external dependencies for basic functionality
Technical optimizations:
- Uses tiktoken with multi-threading for faster tokenization
- Implements aggressive caching and precomputation
- Running mean pooling for efficient semantic chunking
- Modular dependency system (install only what you need)
Benchmarks and code: https://github.com/bhavnicksm/chonkie
Looking for feedback on the architecture and performance optimizations. What other chunking strategies would be useful for RAG applications?
Comments URL: https://news.ycombinator.com/item?id=42100819
Points: 51
# Comments: 18
Connectez-vous pour ajouter un commentaire
Autres messages de ce groupe
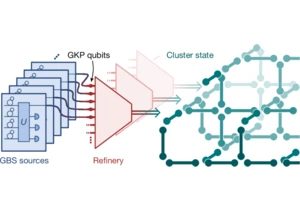
Article URL: https://www.nature.com/articles/s41586-025-09044-5

Article URL: https://t2tmud.org/
Comments URL: https://news.ycombinator.com/item?id=44474919

Article URL: https://simd.info/
Comments URL: https://news.ycombinator.com/item?id=44496229


Article URL: https://random.colorado.edu/
Comments URL: https://news.ycombinator.com/item?

