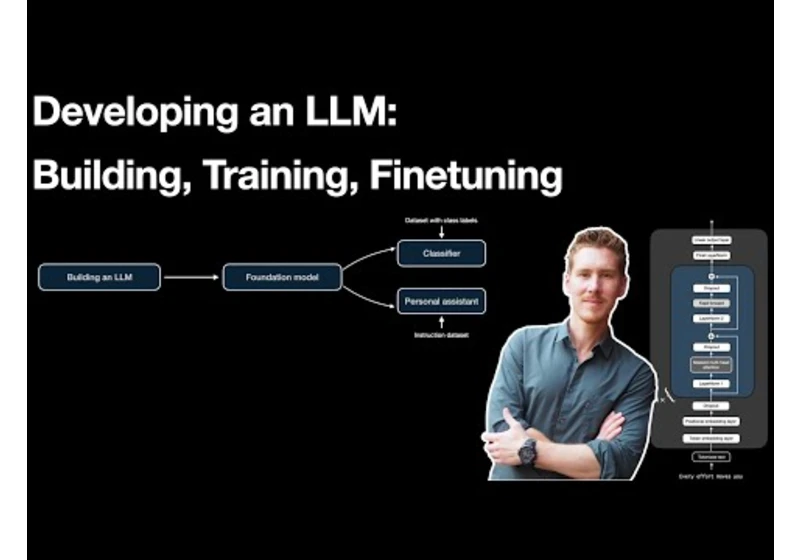
Utworzony 3y | 15 kwi 2022, 18:21:36 Zaloguj się, aby dodać komentarz Inne posty w tej grupie Reinforcement Learning with Human Feedback (RLHF) in 4 minutes 8 lut 2025, 19:40:04 | Sebastian Raschka LLMs: A Journey Through Time and Architecture 24 wrz 2024, 12:40:03 | Sebastian Raschka Building LLMs from the Ground Up: A 3-hour Coding Workshop 31 sie 2024, 12:20:04 | Sebastian Raschka Understanding PyTorch Buffers 27 lip 2024, 23:40:06 | Sebastian Raschka Developing an LLM: Building, Training, Finetuning 6 cze 2024, 13:40:06 | Sebastian Raschka Managing Sources of Randomness When Training Deep Neural Networks 16 kwi 2024, 13:20:05 | Sebastian Raschka Insights from Finetuning LLMs with Low-Rank Adaptation 17 gru 2023, 13:40:03 | Sebastian Raschka Tomas_r2
 in 4 minutes")