Article URL: https://www.pyspur.dev/blog/multi-head-latent-attention-kv-cache-paper-list
Comments URL: https://news.ycombinator.com/item?id=42858741
Points: 109
# Comments: 10
https://www.pyspur.dev/blog/multi-head-latent-attention-kv-cache-paper-list
созданный
1mo
|
29 янв. 2025 г., 00:20:21
Войдите, чтобы добавить комментарий
Другие сообщения в этой группе

Article URL: https://github.com/tearflake/flake-ui
Comments URL: https://news.yco


Article URL: http://www.interdb.jp/pg/index.html
Comments URL: https://news.ycombin

Article URL: https://fintoc.com/codehere
Comments URL: https://news.ycombinator.com/item?id

Article URL: https://www.theguardian.com/games/2025/mar/03/

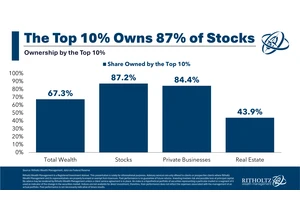
Article URL: https://awealthofcommonsense.com/2025/02/the-top-10/
